- Главная
- Новости
- Telegram
- Viber
- ВКонтакте
- Скопировать ссылку
Восстание машин отменяется: мы все еще нужны ИИ
Если вы из тех, кто волнуется о будущем человечества и кого пугает стремительное развитие ИИ, эта новость вас утешит: без нас роботы стремительно деградируют. Рассказываем о новом исследовании Google DeepMind.
В чем суть?
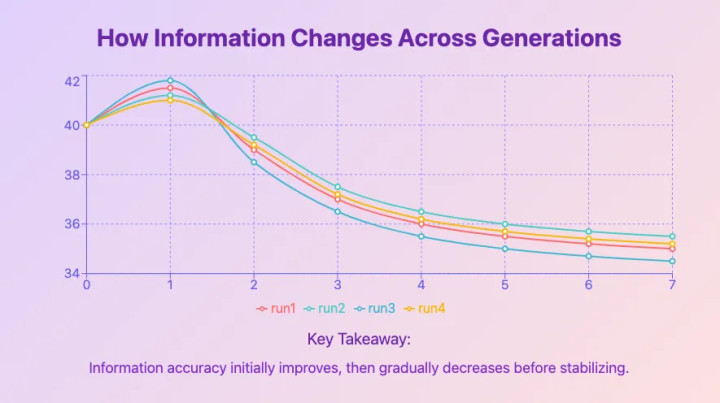
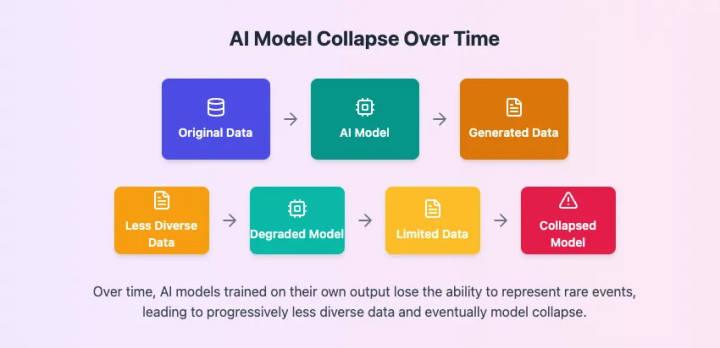
Исследователи из Google DeepMind под руководством Ильи Шумайлова рассказали о критической проблеме, которая может повлиять на будущее искусственного интеллекта, она получила название "коллапс модели". Этому явлению посвящено большое исследование, опубликованное в журнале Nature. Оно возникает, когда большие языковые модели (LLM) обучаются преимущественно на данных, сгенерированных другими ИИ-моделями. Исследование показало дегенеративный процесс, при котором качество и надежность моделей ИИ ухудшаются в последующих поколениях. Более того, проблема становится все более ощутимой, по мере того, как растут объемы использования нейросетей, как частными лицами, так и крупными корпорациями.
Коллапс модели означает что LLM, обученные на данных, созданных другими ИИ-моделями, начинают терять способность генерировать точный и разнообразный контент. Со временем они начинают неправильно интерпретировать реальность и производить повторяющиеся, бессмысленные результаты. Исследование подчеркивает, что данные, сгенерированные ИИ, могут "загрязнять" обучающие наборы данных новых моделей. Это загрязнение приводит к потере богатства и разнообразия, присущих контенту, созданному человеком, заставляя модели "забывать" менее распространенные, но важные элементы. Мы знаем уже немало случаев, когда ИИ пишут рекламные материалы, дипломные работы и целые книги — и все это недобросовестные пользователи выдают за собственный труд, так что со временем проблема будет только усугубляться.
Почему это важно?
Обнаруженное явление может замедлить прогресс в области машинного обучения. По мере того как все больше контента, созданного ИИ, попадает в обучающие наборы данных, шум и неточности будут препятствовать разработке более сложных и надежных систем ИИ. Исследователи подчеркивают, что хотя обычные пользователи могут не сразу заметить эффект, долгосрочные последствия для развития ИИ значительны. Шумайлов призвал компании, работающие в сфере машинного обучения и искусственного интеллекта, серьезно отнестись к этой проблеме и учитывать важность контента, созданного человеком, в обучающих наборах данных.
Для снижения риска коллапса, крайне важно тщательно отбирать и фильтровать данные, используемые для обучения моделей ИИ. Акцент на контенте, созданном человеком, может помочь сохранить разнообразие и точность данных.
Что дальше?
Авторы исследования отмечают, что для полного понимания воздействия коллапса модели и разработки стратегий по его предотвращению требуется дополнительный анализ. Он включает изучение различных архитектур моделей и процессов обучения, которые могли бы противостоять дегенеративным эффектам данных, сгенерированных ИИ. И все же, самым важным в обучении ИИ остается баланс между использованием контента, созданного ИИ, и сохранением разнообразного человеческого творчества.
Другими словами, мы все еще остаемся нужны друг другу: ИИ-модели способны упростить быт и работу человечества, но и креативность и умение нестандартно мыслить, присущее человеческому разуму позволяет LLM совершенствоваться.

{kind=link}
{kind=link}
Комментарии
Чтобы оставлять комментарии,
пожалуйста авторизуйтесь.
Отменяю отмену скайнета.
Вроде как и так логично, что для их поддержания нужен человек