Большая языковая модель (LLM): как работают чат-боты
Хотим мы того или нет, но нейросети и продукты, их использующие, уже вошли в нашу жизнь и теперь мы можем лишь получше разобраться в принципах работы некоторых из них, чтобы использовать максимально эффективно. Например, больших языковых моделей, которые лежат в основе все более популярных чат-ботов.
Большая языковая модель — что это
Большие языковые модели (Large Language Models или LLM) представляют собой огромные массивы данных и алгоритмы, используемые для обработки естественного человеческого языка и генерации ответов на том же языке. Самые известные языковые модели, о которых вы, скорее всего, слышали это BERT от Google, GPT-3, ELMo и ULMFiT. По мере своего развития, речь ботов действительно становится все более естественной, но это вовсе не означает, что у них появляется сознание. Ниже разбираемся, как языковые модели генерируют ответы и за счет чего они “умнеют”.
Как работают LLM?
Прежде чем языковую модель можно будет использовать, ее нужно обучить. Для этого используются массивы текстовых данных: книги, научные статьи, журналы, разнообразные онлайн-сообщения. Все эти данные трансформируются в миллионы параметров, которыми оперирует программа для генерации своих ответов. Два других важных аспекта в работе LLM — «подкрепление» и «предсказание следующего слова». Проще говоря, модель учится предсказывать следующий элемент в последовательности на основе предыдущих элементов, заложенных в нее знаний и паттернов, а также с учетом значимости каждого конкретного слова в пользовательском запросе. По сути, это ключевой момент в обучении языковых моделей, использующих трансформерную архитектуру, например, GPT (Generative Pre-trained Transformer).
Но ведь сгенерированные тексты получаются не просто складными, но и осмысленными, верно? Да, этого получается добиться еще на этапе обучения нейросети, когда все заложенные в нее данные разбиваются на отдельные элементы — токены. Токеном называется минимальная единица, которой может оперировать LLM — это отдельный символ, буква или целое слово. Чем большим количеством токенов может оперировать система, тем она “умнее”. Далее каждый токен преобразуется в соответствующий эмбеддинг. Эмбеддинги представляют собой числовые векторы, представляющие слова или токены в многомерном пространстве. Близкие по смыслу и значению слова будут находится рядом в этом пространстве. Так формируются связи между словами и смыслами, система распознает синонимы и близкие значения, учится перефразировать имеющиеся тексты.
Более того, анализируя массивы данных, LLM учится не только собирать слова в фразы, но и запоминает правильный порядок слов в предложениях для каждого конкретного языка, различные структуры текстов, стили и стандартные конструкции, в том числе, для языков программирования.
В зависимости от целей конкретной LLM, ее настройки могут отличаться. Например, BERT ориентирован на систематизацию информации, классификацию текстов и ответов, DALL-E от OpenAI использует мультимодальный подход, так как работает с разными типами информации на входе и на выходе (изображения и текст), а ChatGPT предлагает максимально естественную речь.
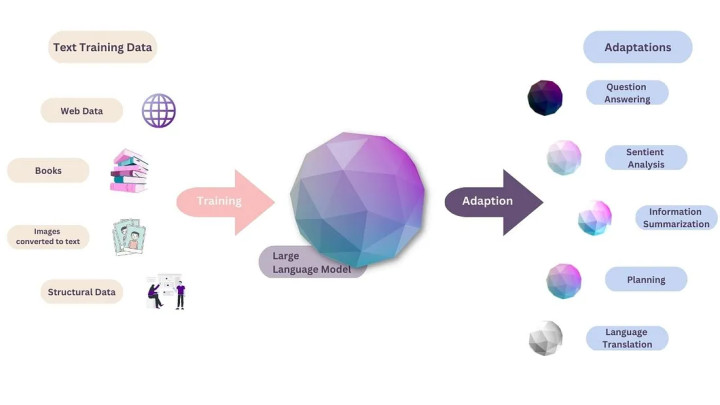
Где применяются LLM?
Хотя мы привыкли говорить о языковых моделях в контексте чат-ботов, сфера их применения гораздо шире и вовсе необязательно взаимодействие с LLM должно быть оформлено в виде диалога.
Языковые модели можно использовать для перевода и локализации разнообразных продуктов, как то веб-сайты, приложения или игры. При этом будут учитываться особенности обоих языков, а подача информации будет максимально естественной.
LLM применимы для создания различных видов текстового контента, таких как статьи, блоги, рецензии, резюме, рекламные тексты и т.д. Есть возможность подводить итоги для длинных текстов, которые вам просто лень читать полностью
Большие языковые модели могут использоваться для образовательных и обучающих целей, таких как подготовка к экзаменам, проверка знаний, создание учебных материалов и т.д. Например, языковая модель может сгенерировать вопросы и ответы по определенной теме, проверить правильность написания или грамматики текста, создать упражнения или тесты по изучаемому предмету или языку.
И все это не говоря о самых разнообразных развлечениях, таких как создание диалогов, сценариев, стихов, песен, шуток и т.д. Например, языковая модель может сгенерировать диалог между двумя персонажами в игре или фильме, сценарий для короткометражки или подкаста, стих или песню на заданную тему или в заданном стиле, шутку или анекдот на определенный случай. Впрочем, творческие задачи все еще плохо поддаются нейросетям, а результат, как правило, выглядит довольно нелепо.
А где LLM не стоит использовать?
Несмотря на все неоспоримые преимущества, возможности больших языковых моделей нельзя применять бездумно. Они не обладают специальными знаниями и склонны к галлюцинациям — так называют состояние, когда нейросеть подменяет данные и совершает ошибки. Именно из-за подобных ошибок LLM нельзя использовать в медицине и других сферах деятельности, связанных с риском для жизни и здоровья человека, а также для любых прогнозов, например, трейдинга.
Если же вы используете продукты на основе LLM, не забывайте перепроверять всю информацию, которую вам предлагает ИИ, как на предмет подлинности фактов, так и на плагиат, которым нейросети тоже порой грешат.

Как видим, хоть большие языковые модели, как и многие другие современные технологии, похожи на магию или кажутся разумными — все это лишь иллюзия. LLM — набор алгоритмов, баз данных и колоссальный человеческий труд, который в них вложен. Если было интересно, подпишитесь на наш канал в Telegram, а если хотите узнать больше о других популярных технологиях, расскажите об этом в комментариях.

Комментарии
Чтобы оставлять комментарии,
пожалуйста авторизуйтесь.
..